This notebook is available on GitHub.
Interactive online version:
![]()
KL Divergence: Gaussian¶
In this example we show how the KL divergence of the surrogate model improves as a function of iteration.
[1]:
import alabi
from alabi.core import SurrogateModel
from alabi import benchmarks as bm
from alabi import metrics
import numpy as np
import matplotlib.pyplot as plt
import multiprocessing as mp
from functools import partial
from scipy.stats import multivariate_normal
We will check how the GP converges on a 4-dimensional Gaussian after 10, 20, 30… iterations
[2]:
ncore = 1
ndim = 4
ntrain = 10 # number of initial training samples
nbatch = 5 # number of active learning iterations * 100
niter_per_batch = 10 # number of iterations per batch
# Define the multivariate normal likelihood function
mean = np.zeros(ndim)
cov = bm.random_gaussian_covariance(ndim)
lnlike = partial(multivariate_normal.logpdf, mean=mean, cov=cov)
print("mean:", mean)
print("cov:", cov)
mean: [0. 0. 0. 0.]
cov: [[ 0.8414129 -0.33304198 0.10790599 0.16416321]
[-0.33304198 1.03456341 -0.16338963 0.47298839]
[ 0.10790599 -0.16338963 0.802922 -0.16358507]
[ 0.16416321 0.47298839 -0.16358507 0.39199966]]
Define alabi settings and run function¶
[3]:
gp_kwargs = {"kernel": "ExpSquaredKernel",
"fit_amp": True,
"fit_mean": True,
"fit_white_noise": False,
"white_noise": -12,
"gp_opt_method": "l-bfgs-b",
"gp_scale_rng": [-2,2],
"optimizer_kwargs": {"max_iter": 50, "xatol": 1e-4, "fatol": 1e-3, "adaptive": True}}
al_kwargs={"algorithm": "bape",
"gp_opt_freq": 10,
"obj_opt_method": "nelder-mead",
"nopt": 1,
"optimizer_kwargs": {"max_iter": 50, "xatol": 1e-3, "fatol": 1e-2, "adaptive": True}}
gp_opt_method = gp_kwargs["gp_opt_method"]
obj_opt_method = al_kwargs["obj_opt_method"]
save_base = f"convergence_results"
def run_alabi(ndim, with_mcmc=True):
savedir = f"{save_base}/multivariate_normal_{ndim}d/"
dynesty_sampler_kwargs = {"bound": "single",
"nlive": 50*ndim,
"sample": "auto"}
dynesty_run_kwargs = {"wt_kwargs": {'pfrac': 1.0},
"stop_kwargs": {'pfrac': 1.0},
"maxiter": int(2e4),
"dlogz_init": 0.5}
# Train surrogate model
sm = SurrogateModel(lnlike_fn=lnlike,
bounds=[(-3., 3.) for _ in range(ndim)],
savedir=savedir,
cache=True,
verbose=True,
ncore=ncore)
# Initialize surrogate model
sm.init_samples(ntrain=ntrain, sampler="sobol")
sm.init_gp(**gp_kwargs)
if not with_mcmc:
# Active training on surrogate model
sm.active_train(niter=int(nbatch*niter_per_batch), **al_kwargs)
else:
for _ in range(nbatch):
# Active training on surrogate model
sm.active_train(niter=niter_per_batch, **al_kwargs)
# Run MCMC on surrogate likelihood function
sm.run_dynesty(like_fn=sm.surrogate_log_likelihood,
sampler_kwargs=dynesty_sampler_kwargs,
run_kwargs=dynesty_run_kwargs)
return sm
[4]:
sm = run_alabi(ndim, with_mcmc=True)
Initialized GP with squared exponential kernel.
Successfully initialized GP on attempt 1
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
Running 10 active learning iterations using bape...
90%|█████████ | 9/10 [00:00<00:00, 85.22it/s]
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
100%|██████████| 10/10 [00:00<00:00, 20.13it/s]
Train MSE: 1.0624373005602084e-15
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Initializing dynesty with self.surrogate_log_likelihood surrogate model as likelihood.
Initialized dynesty DynamicNestedSampler.
Running dynesty with 200 live points on 1 cores...
Run 1: Need 10000 more samples...
==================================================
13024it [05:24, 40.08it/s, batch: 13 | bound: 86 | nc: 1 | ncall: 1291953 | eff(%): 1.006 | loglstar: -7.061 < 0.240 < -0.750 | logz: -9.307 +/- 0.080 | stop: 0.923]
Run 1 complete: 13024 samples, logZ = -9.323
Total accumulated samples: 13024
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Saved dynesty samples to convergence_results/multivariate_normal_4d//dynesty_samples_final_surrogate_iter_10.npz
Running 10 active learning iterations using bape...
80%|████████ | 8/10 [00:00<00:00, 78.15it/s]
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
100%|██████████| 10/10 [00:00<00:00, 17.00it/s]
Train MSE: 6.267890351014464e-15
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Initializing dynesty with self.surrogate_log_likelihood surrogate model as likelihood.
Initialized dynesty DynamicNestedSampler.
Running dynesty with 200 live points on 1 cores...
Run 1: Need 10000 more samples...
==================================================
12703it [00:10, 1154.98it/s, batch: 13 | bound: 9 | nc: 1 | ncall: 29175 | eff(%): 43.361 | loglstar: 61.502 < 68.504 < 67.592 | logz: 58.032 +/- 0.085 | stop: 0.967]
Run 1 complete: 12703 samples, logZ = 58.023
Total accumulated samples: 12703
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Saved dynesty samples to convergence_results/multivariate_normal_4d//dynesty_samples_final_surrogate_iter_20.npz
Running 10 active learning iterations using bape...
0%| | 0/10 [00:00<?, ?it/s]
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
100%|██████████| 10/10 [00:00<00:00, 20.60it/s]
Train MSE: 6.238968157832861e-15
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Initializing dynesty with self.surrogate_log_likelihood surrogate model as likelihood.
Initialized dynesty DynamicNestedSampler.
Running dynesty with 200 live points on 1 cores...
Run 1: Need 10000 more samples...
==================================================
12791it [00:10, 1235.83it/s, batch: 13 | bound: 11 | nc: 1 | ncall: 29642 | eff(%): 43.017 | loglstar: 69.092 < 76.239 < 75.562 | logz: 65.624 +/- 0.087 | stop: 0.967]
Run 1 complete: 12791 samples, logZ = 65.651
Total accumulated samples: 12791
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Saved dynesty samples to convergence_results/multivariate_normal_4d//dynesty_samples_final_surrogate_iter_30.npz
Running 10 active learning iterations using bape...
0%| | 0/10 [00:00<?, ?it/s]
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
100%|██████████| 10/10 [00:00<00:00, 20.83it/s]
Train MSE: 1.3753303915528212e-13
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Initializing dynesty with self.surrogate_log_likelihood surrogate model as likelihood.
Initialized dynesty DynamicNestedSampler.
Running dynesty with 200 live points on 1 cores...
Run 1: Need 10000 more samples...
==================================================
12645it [00:10, 1169.84it/s, batch: 14 | bound: 9 | nc: 1 | ncall: 30603 | eff(%): 41.023 | loglstar: 37.414 < 44.322 < 43.276 | logz: 34.573 +/- 0.082 | stop: 0.970]
Run 1 complete: 12645 samples, logZ = 34.566
Total accumulated samples: 12645
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Saved dynesty samples to convergence_results/multivariate_normal_4d//dynesty_samples_final_surrogate_iter_40.npz
Running 10 active learning iterations using bape...
0%| | 0/10 [00:00<?, ?it/s]
Optimizing GP hyperparameters using 5-fold cross-validation...
Evaluating 100 hyperparameter candidates using 5-fold CV...
100%|██████████| 10/10 [00:00<00:00, 20.53it/s]
Train MSE: 3.492096251884566e-12
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Initializing dynesty with self.surrogate_log_likelihood surrogate model as likelihood.
Initialized dynesty DynamicNestedSampler.
Running dynesty with 200 live points on 1 cores...
Run 1: Need 10000 more samples...
==================================================
12435it [00:13, 899.42it/s, batch: 13 | bound: 14 | nc: 1 | ncall: 41933 | eff(%): 29.493 | loglstar: 2.182 < 9.488 < 8.471 | logz: 2.115 +/- 0.069 | stop: 0.934]
Run 1 complete: 12435 samples, logZ = 2.087
Total accumulated samples: 12435
Caching model to convergence_results/multivariate_normal_4d/surrogate_model...
Saved dynesty samples to convergence_results/multivariate_normal_4d//dynesty_samples_final_surrogate_iter_50.npz
Measure convergence using KL divergence metric¶
Compute the KL divergence between the surrogate model Gaussian (\(P\)) and the true Gaussian (\(Q\)) using the means and covariances:
where \(K_1\) is the covariance matrix of \(P\), \(K_2\) is the covariance matrix of \(Q\), and \(\mu = \mu_1 - \mu_2\) is the difference in the mean of \(P\) and \(Q\).
If \(D_{\rm KL}(P \Vert Q) = 0\), then the two distributions are identical, whereas a larger KL divergence value indicates greater divergence.
[5]:
batches = np.arange(ntrain, int(nbatch * niter_per_batch)+1, niter_per_batch)
metric = alabi.metrics.kl_divergence_gaussian
savedir = f"{save_base}/multivariate_normal_{ndim}d/"
kl_divergence = []
for it in batches:
dynesty_samples_model = np.load(f"{savedir}dynesty_samples_final_surrogate_iter_{it}.npz")["samples"]
kl_div = metrics.kl_divergence_gaussian(mean, cov, dynesty_samples_model.mean(axis=0), np.cov(dynesty_samples_model, rowvar=False))
kl_divergence.append(kl_div)
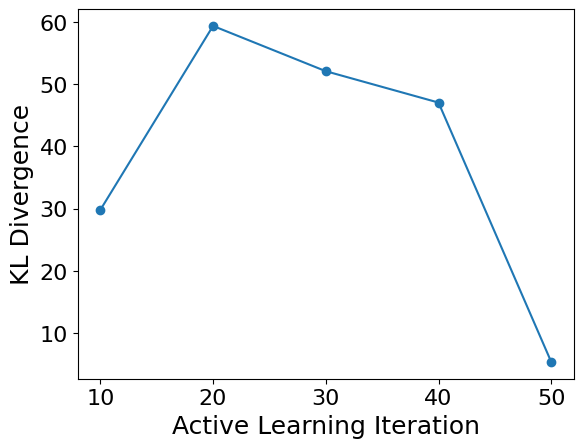
Plot KL divergence vs. iteration. For this 4D Gaussian example it takes roughly ~30 active learning iterations for the surrogate model to converge.
[6]:
plt.plot(batches, kl_divergence, marker='o')
plt.xlabel("Active Learning Iteration", fontsize=18)
plt.ylabel("KL Divergence", fontsize=18)
plt.show()